2025. 1. 4. 18:55ㆍMemorizing/Jetson
아래의 레포지토리를 기반으로 구현했다.
https://github.com/RichardoMrMu/deepsort-tensorrt
GitHub - RichardoMrMu/deepsort-tensorrt: A C++ implementation of Deepsort in Jetson Xavier nx and Jetson nano
A C++ implementation of Deepsort in Jetson Xavier nx and Jetson nano - RichardoMrMu/deepsort-tensorrt
github.com
먼저 두 개의 레포지토리를 클론한다.
git clone git@github.com:ZQPei/deep_sort_pytorch.git
git clone https://github.com/RichardoMrMu/deepsort-tensorrt.git그 후, 클론한 deep_sort_pytorch로 가서 아래의 파일을 복사한 후, 실행한다. use_cuda의 인자를 바꾸어주어야한다.
import os
import cv2
import time
import argparse
import torch
import numpy as np
from deep_sort import build_tracker
from utils.draw import draw_boxes
from utils.parser import get_config
from tqdm import tqdm
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--config_deepsort", type=str, default="./configs/deep_sort.yaml", help='Configure tracker')
parser.add_argument("--cpu", dest="use_cuda", action="store_false", default=True, help='Run in CPU')
args = parser.parse_args()
cfg = get_config()
cfg.merge_from_file(args.config_deepsort)
use_cuda = args.use_cuda and torch.cuda.is_available()
torch.set_grad_enabled(False)
model = build_tracker(cfg, use_cuda=use_cuda)
model.reid = True
model.extractor.net.eval()
device = 'cuda'
output_onnx = 'deepsort.onnx'
# ------------------------ export -----------------------------
print("==> Exporting model to ONNX format at '{}'".format(output_onnx))
input_names = ['input']
output_names = ['output']
input_tensor = torch.randn(1, 3, 128, 64, device=device)
torch.onnx.export(model.extractor.net.cuda(), input_tensor, output_onnx, export_params=True, verbose=False,
input_names=input_names, output_names=output_names, opset_version=10,
do_constant_folding=True,
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}})위의 파이썬 파일을 실행하기 위해선 easydict, tqdm, onnx, torchvision 라이브러리가 설치되어있어야하는데, torchvision은 torch 버전에 맞게 설치해주어야한다.
Jetpack 5.1 기준으로 Pytorch는 2.0.0을 설치해야하고 그에 맞는 torchvision 버전은 0.15.1이다.
Jetpack 6.1 기준으로 Pytorch는 2.3을 설치해야하고 torchvision은 0.18.0을 설치해야한다.링크에서 다운받을 수 있다.)
PyTorch for Jetson
Below are pre-built PyTorch pip wheel installers for Jetson Nano, TX1/TX2, Xavier, and Orin with JetPack 4.2 and newer. Download one of the PyTorch binaries from below for your version of JetPack, and see the installation instructions to run on your Jetson
forums.developer.nvidia.com
아무튼 위의 파이썬 파일을 실행하면 아래의 에러가 발생한다.
Traceback (most recent call last):
File "exportOnnx.py", line 24, in <module>
model = build_tracker(cfg, use_cuda=False)
File "/home/mingi/workspace/deep_sort_pytorch/deep_sort/__init__.py", line 7, in build_tracker
if cfg.USE_FASTREID:
AttributeError: 'YamlParser' object has no attribute 'USE_FASTREID'먼저, cfg yaml 파일을 찍어보면 아래와 같다.
cfg: {'merge_from_file': <bound method YamlParser.merge_from_file of {...}>, 'merge_from_dict': <bound method YamlParser.merge_from_dict of {...}>, 'DEEPSORT': {'REID_CKPT': './deep_sort/deep/checkpoint/ckpt.t7', 'MAX_DIST': 0.2, 'MIN_CONFIDENCE': 0.5, 'NMS_MAX_OVERLAP': 0.5, 'MAX_IOU_DISTANCE': 0.7, 'MAX_AGE': 70, 'N_INIT': 3, 'NN_BUDGET': 100 }}위의 yaml 파일에는 FASTREID라는 인자도 없고, 심지어 이 인자는 DEEPSORT에서 접근가능하다. 따라서 두 가지를 수정해주어야한다.
1. deep_sort_pytorch 레포지토리의 confgs > deep_sort.yaml을 아래와 같이 수정한다.
DEEPSORT:
REID_CKPT: "./deep_sort/deep/checkpoint/ckpt.t7"
MAX_DIST: 0.2
MIN_CONFIDENCE: 0.5
NMS_MAX_OVERLAP: 0.5
MAX_IOU_DISTANCE: 0.7
MAX_AGE: 70
N_INIT: 3
NN_BUDGET: 100
USE_FASTREID: False2. deep_sort_pytorch 레포지토리의 deep_sort > __init__.py을 아래와 같이 수정한다.
from .deep_sort import DeepSort
__all__ = ['DeepSort', 'build_tracker']
def build_tracker(cfg, use_cuda):
if cfg.DEEPSORT.USE_FASTREID:
return DeepSort(model_path=cfg.FASTREID.CHECKPOINT, model_config=cfg.FASTREID.CFG,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=use_cuda)
else:
return DeepSort(model_path=cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=use_cuda)결론적으로 위의 파이썬 파일을 실행하면 deepsort.onnx 파일이 생성된다. 이것을 deepsort_tensorrt 레포지토리의 resources 폴더로 이동한 후, 레포지토리의 빌드를 진행한다.
mkdir build
cd build
cmake ..
make
./onnx2engine ../resources/deepsort.onnx ../resources/deepsort.engine빌드 과정에서 나는 아래의 에러가 발생하였다.
[ 6%] Building CXX object CMakeFiles/deepsort.dir/src/deepsort.cpp.o
In file included from /home/mingi/workspace/deepsort-tensorrt/include/model.hpp:5,
from /home/mingi/workspace/deepsort-tensorrt/include/featuretensor.h:9,
from /home/mingi/workspace/deepsort-tensorrt/include/deepsort.h:6,
from /home/mingi/workspace/deepsort-tensorrt/src/deepsort.cpp:1:
/home/mingi/workspace/deepsort-tensorrt/include/datatype.h:28:10: fatal error: Eigen/Core: 그런 파일이나 디렉터리가 없습니다
28 | #include <Eigen/Core>
| ^~~~~~~~~~~~
compilation terminated.
make[2]: *** [CMakeFiles/deepsort.dir/build.make:76: CMakeFiles/deepsort.dir/src/deepsort.cpp.o] 오류 1
make[1]: *** [CMakeFiles/Makefile2:87: CMakeFiles/deepsort.dir/all] 오류 2
make: *** [Makefile:91: all] 오류 2링킹 오류가 나서 Eigen을 설치했다.
sudo apt update
sudo apt install libeigen3-dev또 아래의 에러가 발생했다..
Jetpack 5.1.1에서의 에러
[ 80%] Building CXX object CMakeFiles/onnx2engine.dir/onnx2engine.cpp.o
In file included from /home/mingi/workspace/deepsort-tensorrt/onnx2engine.cpp:5:
/home/mingi/workspace/deepsort-tensorrt/include/logging.h:239:10: error: looser exception specification on overriding virtual function ‘virtual void Logger::log(nvinfer1::ILogger::Severity, const char*)’
239 | void log(Severity severity, const char* msg) override
| ^~~
In file included from /usr/include/aarch64-linux-gnu/NvInferLegacyDims.h:16,
from /usr/include/aarch64-linux-gnu/NvInfer.h:16,
from /home/mingi/workspace/deepsort-tensorrt/onnx2engine.cpp:2:
/usr/include/aarch64-linux-gnu/NvInferRuntimeCommon.h:1533:18: note: overridden function is ‘virtual void nvinfer1::ILogger::log(nvinfer1::ILogger::Severity, const AsciiChar*) noexcept’
1533 | virtual void log(Severity severity, AsciiChar const* msg) noexcept = 0;
| ^~~
make[2]: *** [CMakeFiles/onnx2engine.dir/build.make:76: CMakeFiles/onnx2engine.dir/onnx2engine.cpp.o] 오류 1
make[1]: *** [CMakeFiles/Makefile2:113: CMakeFiles/onnx2engine.dir/all] 오류 2
make: *** [Makefile:91: all] 오류 2위의 에러는 부모 함수는 noexcept 로 선언되어 있지만, 상속 받은 함수는 다르게 선언되어 있어서 발생한 오류였다.
따라서 아래와 같이 logging.h 파일의 239라인을 수정한다.
void log(Severity severity, const char* msg) noexcept override
{
LogStreamConsumer(mReportableSeverity, severity) << "[TRT] " << std::string(msg) << std::endl;
}onnx 파일을 engine 파일로 변환하여 평화롭게 진행될 줄 알았으나.. 어림도 없지.. segmentation fault..
/onnx2engine ../resources/deepsort.onnx ../resources/deepsort.engine
세그멘테이션 오류 (코어 덤프됨)아래의 nvinfer 라이브러리의 createengine함수에서 에러가 발생하였다.
mingi@mingi-desktop:~$ cat ~/workspace/deepsort-tensorrt/onnx2engine.cpp
1 #include <iostream>
2 #include <NvInfer.h>
3 #include "deepsortenginegenerator.h"
4 #include "cuda_runtime_api.h"
5 #include "logging.h"
6
7 using namespace nvinfer1;
8
9 static Logger gLogger;
10
11 int main(int argc, char** argv) {
12 cudaSetDevice(0);
13 if (argc < 3) {
14 std::cout << "./onnx2engine [input .onnx path] [output .engine path]" << std::endl;
15 return -1;
16 }
17 std::string onnxPath = argv[1];
18 std::string enginePath = argv[2];
19 DeepSortEngineGenerator* engG = new DeepSortEngineGenerator(&gLogger);
20 engG->setFP16(true);
21 engG->createEngine(onnxPath, enginePath);
22 std::cout << "==============" << std::endl;
23 std::cout << "| SUCCESS! |" << std::endl;
24 std::cout << "==============" << std::endl;
25 return 0;
26 }
27
28JetPack6에서의 에러
mingi@mingi-desktop:~/workspace/deepsort-tensorrt/build$ ninja -j4
[2/14] Building CXX object CMakeFiles/deepsort.dir/src/featuretensor.cpp.o
FAILED: CMakeFiles/deepsort.dir/src/featuretensor.cpp.o
/usr/bin/c++ -Ddeepsort_EXPORTS -I/usr/local/cuda/include -I/home/mingi/workspace/deepsort-tensorrt/include -I/usr/include/eigen3 -isystem /usr/include/opencv4 -std=c++11 -O3 -DNDEBUG -fPIC -MD -MT CMakeFiles/deepsort.dir/src/featuretensor.cpp.o -MF CMakeFiles/deepsort.dir/src/featuretensor.cpp.o.d -o CMakeFiles/deepsort.dir/src/featuretensor.cpp.o -c /home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::loadEngine(std::string)’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:74:44: error: no matching function for call to ‘nvinfer1::IRuntime::deserializeCudaEngine(const char*, std::__cxx11::basic_string<char>::size_type, std::nullptr_t)’
74 | engine = runtime->deserializeCudaEngine(engineCache.data(), engineCache.size(), nullptr);
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In file included from /usr/include/aarch64-linux-gnu/NvInfer.h:22,
from /home/mingi/workspace/deepsort-tensorrt/include/featuretensor.h:7,
from /home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:1:
/usr/include/aarch64-linux-gnu/NvInferRuntime.h:1483:18: note: candidate: ‘nvinfer1::ICudaEngine* nvinfer1::IRuntime::deserializeCudaEngine(const void*, std::size_t)’
1483 | ICudaEngine* deserializeCudaEngine(void const* blob, std::size_t size) noexcept
| ^~~~~~~~~~~~~~~~~~~~~
/usr/include/aarch64-linux-gnu/NvInferRuntime.h:1483:18: note: candidate expects 2 arguments, 3 provided
/usr/include/aarch64-linux-gnu/NvInferRuntime.h:1501:18: note: candidate: ‘nvinfer1::ICudaEngine* nvinfer1::IRuntime::deserializeCudaEngine(nvinfer1::IStreamReader&)’
1501 | ICudaEngine* deserializeCudaEngine(IStreamReader& streamReader)
| ^~~~~~~~~~~~~~~~~~~~~
/usr/include/aarch64-linux-gnu/NvInferRuntime.h:1501:18: note: candidate expects 1 argument, 3 provided
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::loadOnnx(std::string)’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:104:13: error: ‘class nvinfer1::IBuilderConfig’ has no member named ‘setMaxWorkspaceSize’
104 | config->setMaxWorkspaceSize(1 << 20);
| ^~~~~~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:105:23: error: ‘class nvinfer1::IBuilder’ has no member named ‘buildEngineWithConfig’
105 | engine = builder->buildEngineWithConfig(*network, *config);
| ^~~~~~~~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::initResource()’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:129:26: error: ‘class nvinfer1::ICudaEngine’ has no member named ‘getBindingIndex’
129 | inputIndex = engine->getBindingIndex(inputName.c_str());
| ^~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:130:27: error: ‘class nvinfer1::ICudaEngine’ has no member named ‘getBindingIndex’
130 | outputIndex = engine->getBindingIndex(outputName.c_str());
| ^~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::doInference(float*, float*)’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:146:14: error: ‘class nvinfer1::IExecutionContext’ has no member named ‘setBindingDimensions’
146 | context->setBindingDimensions(0, inputDims);
| ^~~~~~~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:148:14: error: ‘class nvinfer1::IExecutionContext’ has no member named ‘enqueueV2’; did you mean ‘enqueueV3’?
148 | context->enqueueV2(buffers, cudaStream, nullptr);
| ^~~~~~~~~
| enqueueV3
[5/14] Building CXX object CMakeFiles/deepsort.dir/src/kalmanfilter.cpp.o
ninja: build stopped: subcommand failed.[1/4] Building CXX object CMakeFiles/deepsort.dir/src/featuretensor.cpp.o
FAILED: CMakeFiles/deepsort.dir/src/featuretensor.cpp.o
/usr/bin/c++ -Ddeepsort_EXPORTS -I/usr/local/cuda/include -I/home/mingi/workspace/deepsort-tensorrt/include -I/usr/include/eigen3 -isystem /usr/include/opencv4 -std=c++11 -O3 -DNDEBUG -fPIC -MD -MT CMakeFiles/deepsort.dir/src/featuretensor.cpp.o -MF CMakeFiles/deepsort.dir/src/featuretensor.cpp.o.d -o CMakeFiles/deepsort.dir/src/featuretensor.cpp.o -c /home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::loadOnnx(std::string)’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:105:45: error: cannot convert ‘nvinfer1::IHostMemory*’ to ‘nvinfer1::ICudaEngine*’ in assignment
105 | engine = builder->buildSerializedNetwork(*network, *config);
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~
| |
| nvinfer1::IHostMemory*
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::initResource()’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:129:26: error: ‘class nvinfer1::ICudaEngine’ has no member named ‘getBindingIndex’
129 | inputIndex = engine->getBindingIndex(inputName.c_str());
| ^~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:130:27: error: ‘class nvinfer1::ICudaEngine’ has no member named ‘getBindingIndex’
130 | outputIndex = engine->getBindingIndex(outputName.c_str());
| ^~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp: In member function ‘void FeatureTensor::doInference(float*, float*)’:
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:146:14: error: ‘class nvinfer1::IExecutionContext’ has no member named ‘setBindingDimensions’
146 | context->setBindingDimensions(0, inputDims);
| ^~~~~~~~~~~~~~~~~~~~
/home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:148:23: error: no matching function for call to ‘nvinfer1::IExecutionContext::enqueueV3(void* [2], CUstream_st*&, std::nullptr_t)’
148 | context->enqueueV3(buffers, cudaStream, nullptr);
| ~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In file included from /usr/include/aarch64-linux-gnu/NvInfer.h:22,
from /home/mingi/workspace/deepsort-tensorrt/include/featuretensor.h:7,
from /home/mingi/workspace/deepsort-tensorrt/src/featuretensor.cpp:1:
/usr/include/aarch64-linux-gnu/NvInferRuntime.h:4270:10: note: candidate: ‘bool nvinfer1::IExecutionContext::enqueueV3(cudaStream_t)’
4270 | bool enqueueV3(cudaStream_t stream) noexcept
| ^~~~~~~~~
/usr/include/aarch64-linux-gnu/NvInferRuntime.h:4270:10: note: candidate expects 1 argument, 3 provided위의 에러는 현재 TensorRT의 버전과 사용하는 함수의 이름이 안맞아서 발생하는 오류라고한다. TensorRT 8 버전 이상은 다른 함수를 사용해야한다고.. 나의 라이브러리의 정보는 다음과 같았다.
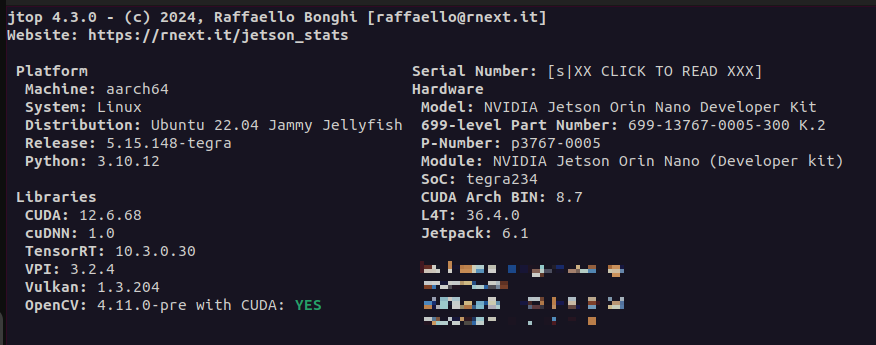
tensorrt는 버전마다 함수의 이름, 인자, 반환값이 너무 천차만별로 달라져서 그것에 맞게 수정해야했다.. 아래의 페이지에서 직접 보고 수정했다..
https://docs.nvidia.com/deeplearning/tensorrt/release-notes/index.html#rel-10-3-0
Release Notes :: NVIDIA Deep Learning TensorRT Documentation
NVIDIA TensorRT is a C++ library that facilitates high performance inference on NVIDIA GPUs. It is designed to work in connection with deep learning frameworks that are commonly used for training. TensorRT focuses specifically on running an already trained
docs.nvidia.com
https://docs.nvidia.com/deeplearning/tensorrt/api/c_api/pages.html
TensorRT: Related Pages
Here is a list of all related documentation pages:
docs.nvidia.com
어쨌든 이래저래 하나씩 해결하면서 아래의 코드로 변경했다.
# 원본 코드
#include "featuretensor.h"
#include <fstream>
using namespace nvinfer1;
#define INPUTSTREAM_SIZE (maxBatchSize*3*imgShape.area())
#define OUTPUTSTREAM_SIZE (maxBatchSize*featureDim)
FeatureTensor::FeatureTensor(const int maxBatchSize, const cv::Size imgShape, const int featureDim, int gpuID, ILogger* gLogger)
: maxBatchSize(maxBatchSize), imgShape(imgShape), featureDim(featureDim),
inputStreamSize(INPUTSTREAM_SIZE), outputStreamSize(OUTPUTSTREAM_SIZE),
inputBuffer(new float[inputStreamSize]), outputBuffer(new float[outputStreamSize]),
inputName("input"), outputName("output") {
cudaSetDevice(gpuID);
this->gLogger = gLogger;
runtime = nullptr;
engine = nullptr;
context = nullptr;
means[0] = 0.485, means[1] = 0.456, means[2] = 0.406;
std[0] = 0.229, std[1] = 0.224, std[2] = 0.225;
initFlag = false;
}
FeatureTensor::~FeatureTensor() {
delete [] inputBuffer;
delete [] outputBuffer;
if (initFlag) {
// cudaStreamSynchronize(cudaStream);
cudaStreamDestroy(cudaStream);
cudaFree(buffers[inputIndex]);
cudaFree(buffers[outputIndex]);
}
}
bool FeatureTensor::getRectsFeature(const cv::Mat& img, DETECTIONS& det) {
std::vector<cv::Mat> mats;
for (auto& dbox : det) {
cv::Rect rect = cv::Rect(int(dbox.tlwh(0)), int(dbox.tlwh(1)),
int(dbox.tlwh(2)), int(dbox.tlwh(3)));
rect.x -= (rect.height * 0.5 - rect.width) * 0.5;
rect.width = rect.height * 0.5;
rect.x = (rect.x >= 0 ? rect.x : 0);
rect.y = (rect.y >= 0 ? rect.y : 0);
rect.width = (rect.x + rect.width <= img.cols ? rect.width : (img.cols - rect.x));
rect.height = (rect.y + rect.height <= img.rows ? rect.height : (img.rows - rect.y));
cv::Mat tempMat = img(rect).clone();
cv::resize(tempMat, tempMat, imgShape);
mats.push_back(tempMat);
}
doInference(mats);
// decode output to det
stream2det(outputBuffer, det);
return true;
}
bool FeatureTensor::getRectsFeature(DETECTIONS& det) {
return true;
}
void FeatureTensor::loadEngine(std::string enginePath) {
// Deserialize model
runtime = createInferRuntime(*gLogger);
assert(runtime != nullptr);
std::ifstream engineStream(enginePath, std::ios::binary);
std::string engineCache("");
while (engineStream.peek() != EOF) {
std::stringstream buffer;
buffer << engineStream.rdbuf();
engineCache.append(buffer.str());
}
engineStream.close();
engine = runtime->deserializeCudaEngine(engineCache.data(), engineCache.size(), nullptr);
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
initResource();
}
void FeatureTensor::loadOnnx(std::string onnxPath) {
auto builder = createInferBuilder(*gLogger);
assert(builder != nullptr);
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = builder->createNetworkV2(explicitBatch);
assert(network != nullptr);
auto config = builder->createBuilderConfig();
assert(config != nullptr);
auto profile = builder->createOptimizationProfile();
Dims dims = Dims4{1, 3, imgShape.height, imgShape.width};
profile->setDimensions(inputName.c_str(),
OptProfileSelector::kMIN, Dims4{1, dims.d[1], dims.d[2], dims.d[3]});
profile->setDimensions(inputName.c_str(),
OptProfileSelector::kOPT, Dims4{maxBatchSize, dims.d[1], dims.d[2], dims.d[3]});
profile->setDimensions(inputName.c_str(),
OptProfileSelector::kMAX, Dims4{maxBatchSize, dims.d[1], dims.d[2], dims.d[3]});
config->addOptimizationProfile(profile);
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, *gLogger);
assert(parser != nullptr);
auto parsed = parser->parseFromFile(onnxPath.c_str(), static_cast<int>(ILogger::Severity::kWARNING));
assert(parsed);
config->setMaxWorkspaceSize(1 << 20);
engine = builder->buildEngineWithConfig(*network, *config);
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
initResource();
}
int FeatureTensor::getResult(float*& buffer) {
if (buffer != nullptr)
delete buffer;
int curStreamSize = curBatchSize*featureDim;
buffer = new float[curStreamSize];
for (int i = 0; i < curStreamSize; ++i) {
buffer[i] = outputBuffer[i];
}
return curStreamSize;
}
void FeatureTensor::doInference(vector<cv::Mat>& imgMats) {
mat2stream(imgMats, inputBuffer);
doInference(inputBuffer, outputBuffer);
}
void FeatureTensor::initResource() {
inputIndex = engine->getBindingIndex(inputName.c_str());
outputIndex = engine->getBindingIndex(outputName.c_str());
// Create CUDA stream
cudaStreamCreate(&cudaStream);
buffers[inputIndex] = inputBuffer;
buffers[outputIndex] = outputBuffer;
// Malloc CUDA memory
cudaMalloc(&buffers[inputIndex], inputStreamSize * sizeof(float));
cudaMalloc(&buffers[outputIndex], outputStreamSize * sizeof(float));
initFlag = true;
}
void FeatureTensor::doInference(float* inputBuffer, float* outputBuffer) {
cudaMemcpyAsync(buffers[inputIndex], inputBuffer, inputStreamSize * sizeof(float), cudaMemcpyHostToDevice, cudaStream);
Dims4 inputDims{curBatchSize, 3, imgShape.height, imgShape.width};
context->setBindingDimensions(0, inputDims);
context->enqueueV2(buffers, cudaStream, nullptr);
cudaMemcpyAsync(outputBuffer, buffers[outputIndex], outputStreamSize * sizeof(float), cudaMemcpyDeviceToHost, cudaStream);
// cudaStreamSynchronize(cudaStream);
}
void FeatureTensor::mat2stream(vector<cv::Mat>& imgMats, float* stream) {
int imgArea = imgShape.area();
curBatchSize = imgMats.size();
if (curBatchSize > maxBatchSize) {
std::cout << "[WARNING]::Batch size overflow, input will be truncated!" << std::endl;
curBatchSize = maxBatchSize;
}
for (int batch = 0; batch < curBatchSize; ++batch) {
cv::Mat tempMat = imgMats[batch];
int i = 0;
for (int row = 0; row < imgShape.height; ++row) {
uchar* uc_pixel = tempMat.data + row * tempMat.step;
for (int col = 0; col < imgShape.width; ++col) {
stream[batch * 3 * imgArea + i] = ((float)uc_pixel[0] / 255.0 - means[0]) / std[0];
stream[batch * 3 * imgArea + i + imgArea] = ((float)uc_pixel[1] / 255.0 - means[1]) / std[1];
stream[batch * 3 * imgArea + i + 2 * imgArea] = ((float)uc_pixel[2] / 255.0 - means[2]) / std[2];
uc_pixel += 3;
++i;
}
}
}
}
void FeatureTensor::stream2det(float* stream, DETECTIONS& det) {
int i = 0;
for (DETECTION_ROW& dbox : det) {
for (int j = 0; j < featureDim; ++j)
dbox.feature[j] = stream[i * featureDim + j];
// dbox.feature[j] = (float)1.0;
++i;
}
}
# 수정된 코드
#include "featuretensor.h"
#include <fstream>
#include <opencv2/opencv.hpp>
using namespace nvinfer1;
#define INPUTSTREAM_SIZE (maxBatchSize*3*imgShape.area())
#define OUTPUTSTREAM_SIZE (maxBatchSize*featureDim)
FeatureTensor::FeatureTensor(const int maxBatchSize, const cv::Size imgShape, const int featureDim, int gpuID, ILogger* gLogger)
: maxBatchSize(maxBatchSize), imgShape(imgShape), featureDim(featureDim),
inputStreamSize(INPUTSTREAM_SIZE), outputStreamSize(OUTPUTSTREAM_SIZE),
inputBuffer(new float[inputStreamSize]), outputBuffer(new float[outputStreamSize]),
inputName("input"), outputName("output") {
cudaSetDevice(gpuID);
this->gLogger = gLogger;
runtime = nullptr;
engine = nullptr;
context = nullptr;
means[0] = 0.485, means[1] = 0.456, means[2] = 0.406;
std[0] = 0.229, std[1] = 0.224, std[2] = 0.225;
initFlag = false;
}
FeatureTensor::~FeatureTensor() {
delete [] inputBuffer;
delete [] outputBuffer;
if (initFlag) {
// cudaStreamSynchronize(cudaStream);
cudaStreamDestroy(cudaStream);
cudaFree(buffers[inputIndex]);
cudaFree(buffers[outputIndex]);
}
}
bool FeatureTensor::getRectsFeature(const cv::Mat& img, DETECTIONS& det) {
std::vector<cv::Mat> mats;
for (auto& dbox : det) {
cv::Rect rect = cv::Rect(int(dbox.tlwh(0)), int(dbox.tlwh(1)),
int(dbox.tlwh(2)), int(dbox.tlwh(3)));
rect.x -= (rect.height * 0.5 - rect.width) * 0.5;
rect.width = rect.height * 0.5;
rect.x = (rect.x >= 0 ? rect.x : 0);
rect.y = (rect.y >= 0 ? rect.y : 0);
rect.width = (rect.x + rect.width <= img.cols ? rect.width : (img.cols - rect.x));
rect.height = (rect.y + rect.height <= img.rows ? rect.height : (img.rows - rect.y));
cv::Mat tempMat = img(rect).clone();
cv::resize(tempMat, tempMat, imgShape);
mats.push_back(tempMat);
}
doInference(mats);
// decode output to det
stream2det(outputBuffer, det);
return true;
}
bool FeatureTensor::getRectsFeature(DETECTIONS& det) {
return true;
}
void FeatureTensor::loadEngine(std::string enginePath) {
// Deserialize model
runtime = createInferRuntime(*gLogger);
assert(runtime != nullptr);
std::ifstream engineStream(enginePath, std::ios::binary);
std::string engineCache("");
while (engineStream.peek() != EOF) {
std::stringstream buffer;
buffer << engineStream.rdbuf();
engineCache.append(buffer.str());
}
engineStream.close();
engine = runtime->deserializeCudaEngine(engineCache.data(), engineCache.size());
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
initResource();
}
void FeatureTensor::loadOnnx(std::string onnxPath) {
auto builder = createInferBuilder(*gLogger);
assert(builder != nullptr);
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = builder->createNetworkV2(explicitBatch);
assert(network != nullptr);
auto config = builder->createBuilderConfig();
assert(config != nullptr);
auto profile = builder->createOptimizationProfile();
Dims dims = Dims4{1, 3, imgShape.height, imgShape.width};
profile->setDimensions(inputName.c_str(),
OptProfileSelector::kMIN, Dims4{1, dims.d[1], dims.d[2], dims.d[3]});
profile->setDimensions(inputName.c_str(),
OptProfileSelector::kOPT, Dims4{maxBatchSize, dims.d[1], dims.d[2], dims.d[3]});
profile->setDimensions(inputName.c_str(),
OptProfileSelector::kMAX, Dims4{maxBatchSize, dims.d[1], dims.d[2], dims.d[3]});
config->addOptimizationProfile(profile);
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, *gLogger);
assert(parser != nullptr);
auto parsed = parser->parseFromFile(onnxPath.c_str(), static_cast<int>(ILogger::Severity::kWARNING));
assert(parsed);
auto serializedModel = builder->buildSerializedNetwork(*network, *config);
engine = runtime->deserializeCudaEngine(serializedModel->data(), serializedModel->size());
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
initResource();
}
int FeatureTensor::getResult(float*& buffer) {
if (buffer != nullptr)
delete buffer;
int curStreamSize = curBatchSize*featureDim;
buffer = new float[curStreamSize];
for (int i = 0; i < curStreamSize; ++i) {
buffer[i] = outputBuffer[i];
}
return curStreamSize;
}
void FeatureTensor::doInference(vector<cv::Mat>& imgMats) {
mat2stream(imgMats, inputBuffer);
doInference(inputBuffer, outputBuffer);
}
void FeatureTensor::initResource() {
// TensorRT 8.x 이상에서 사용하는 방법
for (int i = 0; i < engine->getNbIOTensors(); i++) {
const char* tensorName = engine->getIOTensorName(i);
if (std::string(tensorName) == inputName) {
inputIndex = i;
}
if (std::string(tensorName) == outputName) {
outputIndex = i;
}
}
// Create CUDA stream
cudaStreamCreate(&cudaStream);
buffers[inputIndex] = inputBuffer;
buffers[outputIndex] = outputBuffer;
// Malloc CUDA memory
cudaMalloc(&buffers[inputIndex], inputStreamSize * sizeof(float));
cudaMalloc(&buffers[outputIndex], outputStreamSize * sizeof(float));
initFlag = true;
}
void FeatureTensor::doInference(float* inputBuffer, float* outputBuffer) {
cudaMemcpyAsync(buffers[inputIndex], inputBuffer, inputStreamSize * sizeof(float), cudaMemcpyHostToDevice, cudaStream);
Dims4 inputDims{curBatchSize, 3, imgShape.height, imgShape.width};
context->setInputShape(inputName.c_str(), inputDims);
context->enqueueV3(cudaStream);
cudaMemcpyAsync(outputBuffer, buffers[outputIndex], outputStreamSize * sizeof(float), cudaMemcpyDeviceToHost, cudaStream);
// cudaStreamSynchronize(cudaStream);
}
void FeatureTensor::mat2stream(vector<cv::Mat>& imgMats, float* stream) {
int imgArea = imgShape.area();
curBatchSize = imgMats.size();
if (curBatchSize > maxBatchSize) {
std::cout << "[WARNING]::Batch size overflow, input will be truncated!" << std::endl;
curBatchSize = maxBatchSize;
}
for (int batch = 0; batch < curBatchSize; ++batch) {
cv::Mat tempMat = imgMats[batch];
int i = 0;
for (int row = 0; row < imgShape.height; ++row) {
uchar* uc_pixel = tempMat.data + row * tempMat.step;
for (int col = 0; col < imgShape.width; ++col) {
stream[batch * 3 * imgArea + i] = ((float)uc_pixel[0] / 255.0 - means[0]) / std[0];
stream[batch * 3 * imgArea + i + imgArea] = ((float)uc_pixel[1] / 255.0 - means[1]) / std[1];
stream[batch * 3 * imgArea + i + 2 * imgArea] = ((float)uc_pixel[2] / 255.0 - means[2]) / std[2];
uc_pixel += 3;
++i;
}
}
}
}
void FeatureTensor::stream2det(float* stream, DETECTIONS& det) {
int i = 0;
for (DETECTION_ROW& dbox : det) {
for (int j = 0; j < featureDim; ++j)
dbox.feature[j] = stream[i * featureDim + j];
// dbox.feature[j] = (float)1.0;
++i;
}
}그리고 아래의 명령어를 통해서 onnx 파일을 tensorrt의 engine 파일로 변환했다.
./onnx2engine ../resources/deepsort.onnx ../resources/deepsort.engine그리고 아래의 명령어를 실행했다.
./demo ../resources/deepsort.engine ../resources/track.txt'Memorizing > Jetson' 카테고리의 다른 글
| Jetson에서 Anaconda 설치하기 (0) | 2025.01.12 |
|---|---|
| IRuntime::deserializeCudaEngine: Error Code 1: Serialization (0) | 2025.01.06 |
| JetPack6에서 Opencv 빌드하기 (0) | 2025.01.04 |
| JetPack 5.1.1 에서 Jetpack 6 설치하기 (0) | 2025.01.03 |
| error: stat(/usr/local/cuda/lib64/libcudart_static.a): Bad message (0) | 2025.01.03 |