BALD(Bayesian Active Learning Disagreement) 논문 해석
2023. 1. 24. 21:36ㆍResearch/Active Learning
Active Learning
- 이미지를 활용한 모델링을 진행하다보면, 비용이 많이 드는 라벨링 작업이 문제가 될 때가 많습니다. 그렇기 때문에 적은 라벨링으로 높은 성능을 기록할 수 있는 모델을 만드는 것이 비용 측면에서 효율적입니다. Active Learning은 라벨링을 진행하지 않은 샘플들 중 정보가 많이 담겨있는 샘플을 선정하는 것을 목표로하는 분야입니다.
Bayesian Active Learning
- Bayesian Active Learning은 Active Learning의 한 갈래로, 정보가 많이 담겨있는 샘플을 선정할 때, Bayesian 방법론을 사용합니다. 즉, 라벨링을 진행하지 않은 샘플들의 불확실성을 Bayesian 방법론을 통하여 측정하고, 불확실성이 높은 샘플들을 먼저 라벨링 해야할 샘플로 선정하는 방식입니다.
BALD(Bayesian Active Learning Disagreement)[1]
- BALD(Bayesian Active Learning Disagreement)는 불확실성을 이용하여 샘플을 선정하는 Bayesian Active Learning에서 가장 널리 이용되고, 수학적으로 안정적인 방법 중 하나입니다. 본 포스팅은 BALD 방법론에 대해 설명하는 것을 목적으로 합니다.
Information Gain
- 정보이론에서 관측치가 얼마나 정보량을 많이 가지고 있는지를 판단하는 목적함수로 Information Gain을 사용하기도 합니다.(e.g. Random Forest Classifier).
- Information Gain은 그림1과 같이 계산할 수 있습니다.
- 좌변은 모든 데이터(D)가 주어졌을 때, 모델의 엔트로피(불확실성)를, 우변은 모든 데이터에서 데이터(x, y)가 관측되었을 때, 모델의 엔트로피를 의미합니다. 우리의 목적은 목적함수 U(x)를 최소화하는 것이므로, 엔트로피가 높은 데이터를 관측(우변의 관점)하면 될 것입니다. 즉, Information Gain을 최소화한다는 것은 모델의 엔트로피를 낮출 수 있는(=정보량이 큰 = 불확실한) 관측치를 관측한다(x, y)는 것과 동치가 됩니다.
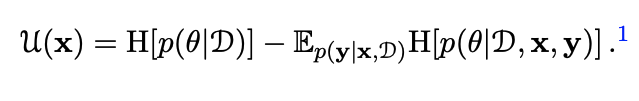
오차함수
오차함수의 도출

- 앞에서 정의한 Information Gain은 수학적으로 모든 데이터와 관측된 x가 주어졌을 때, 모델의 파라미터와 모델의 예측값과의 Mutual Information과 동치가 됩니다(2.9). (2.9)식을 다른 방식으로 전개하면 (2.10)이 됩니다. BALD에서는 (2.10)식을 오차함수로 사용합니다.
BALD 오차함수의 의미
- Information Gain의 입장에서 생각해볼 때, 예측값의 불확실성이 높은 관측치를 뽑는 것이 목적이 되는데, 이는 (2.10)에서도 유효합니다.
- (2.10)의 좌변에서는 샘플에 대해 불확실성을 낮추는 방향으로 파라미터를 업데이트 해야합니다. 하지만 우변에서는 예측값의 우도의 불확실성을 높여줄 수 있는 파라미터 세타를 뽑아야 합니다. 좌변에서 동작하는 파라미터 세타와 우변에서 동작하는 파라미터 세타가 반대로 움직(서로 Disagree 하다.)이므로, by Disagreement라는 방법론의 이름이 붙게되었습니다.
Reference
[1] HOULSBY, Neil, et al. Bayesian active learning for classification and preference learning. arXiv preprint arXiv:1112.5745, 2011.