2023. 2. 18. 11:03ㆍResearch/Continual Learning
본 글은 Continual Learning에 대한 Survey를 정리한 글이며, [1]을 참고하였습니다.
Background
- '과제'(Task)라는 개념은 새로운 클래스 그룹, 새로운 도메인 또는 다른 출력 공간에 속하는 새로운 데이터 배치가 있는 격리된 교육 단계를 나타냅니다.
- Continual Learning은 문헌에 따라 다르게 표현(e.g. Lifelong Learning, Incremental Learning)되기도 합니다.
Continual Learning Scenario

Task IL
입력 이미지와 어떤 태스크 인지가 주어지고, 그것이 첫 번째 클래스인지 두 번째 클래스 인지를 맞추는 문제입니다.
Class IL
입력 이미지만 주어졌을 때, 어떤 클래스 인지를 맞추는 문제입니다.
Domain IL
입력 이미지만 주어졌을 때, 그것이 첫 번째 클래스인지 두 번째 클래스 인지를 맞추는 문제입니다.
Continual Learning Approaches
Replay Methods
이 방법은 샘플을 원시 형식으로 저장하거나 생성 모델을 사용하여 의사 샘플을 생성합니다. 이러한 이전 작업 샘플은 망각을 완화하기 위해 새로운 작업을 학습하는 동안 사용됩니다. 그것들은 이전 데이터에 대한 정보를 전달해주기 위해 모델 입력으로 재사용되거나 이전 작업 간섭을 방지하기 위해 새로운 작업 손실의 최적화를 제한하기 위해 사용됩니다.
Replay Methods 중 널리 알려진 방법은 iCaRL[2]입니다. iCaRL에서는 일반적인 Classification을 위한 모델과는 달리 Nearest Mean of Examplar Classification이라는 방법을 사용합니다. 이는 Exemplar Sets(선별된 이미지 셋)을 모델에 통과시켜 피쳐를 생성하고 각 클래스 별로 피쳐들의 평균을 구한 뒤 새로운 예제가 나오면 각 클래스 피쳐의 평균 중에서 가장 가까운 클래스로 분류하는 방식을 사용합니다.

exemplar set의 원소들을 모두 프로젝션 시켜 y클래스 피쳐들의 평균을 구합니다. 그리고 새로운 이미지 x가 들어왔을 때, 각 클래스 피쳐들의 평균과의 거리를 바탕으로 거리가 가장 작은 클래스를 새로운 클래스로 할당합니다.

새로운 클래스(s, …, t)가 들어왔을 때, 클래스s의 샘플들을 이용하여 강건한 샘플들을 골라서(construct exemplarset함수 참고) 각 클래스의 exemplar set으로 업데이트하게 됩니다.

Regularization based methods
Regularization based methods는 Replay methods들과 달리 이미지를 저장하여 기억하는 과정이 없고, 가중치를 업데이트 할 때, 기존 모델의 가중치를 이용하여 Regularization 하는 방법을 사용합니다.
가장 대표적인 방법은 EWC(Elastic Weight Consolidation)[3]입니다. 작업 A를 학습한 후 작업 B를 학습할 때, penalty없이 학습을 진행하게 되면 작업 B에 대해서만 잘 수행하게되고, L2 Regularization을 수행하면, 작업 A, 작업 B 모두 잘 수행하지 못하는 상태가 됩니다. 하지만, 본 논문에서 제안하는 EWC 방법을 쓰게되면, 작업 A, 작업 B 모두 잘 수행할 수 있습니다.

기존 태스크의 변화량의 변화율(2차 미분값)을 regularization term으로 줌으로써 급격하게 변하는 A를 많이 업데이트 하지 못하게함으로써 Catastopic forgetting을 방지했습니다. 2차 미분값은 계산하는 것이 불가능(intractable)하기 때문에 본 논문에서는 2차 미분값의 근사치로 피셔 정보 매트릭스를 사용하였습니다.

Parameter isolation methods
Replay methods들과 달리 이미지를 저장하여 기억하는 과정이 없고, 새로운 Task가 들어왔을 때, 그 Task에 맞는 네트워크를 추가하여 구성하여 새로운 Task가 추가됨에따라 적응적으로 변화하는 네트워크를 구성합니다.
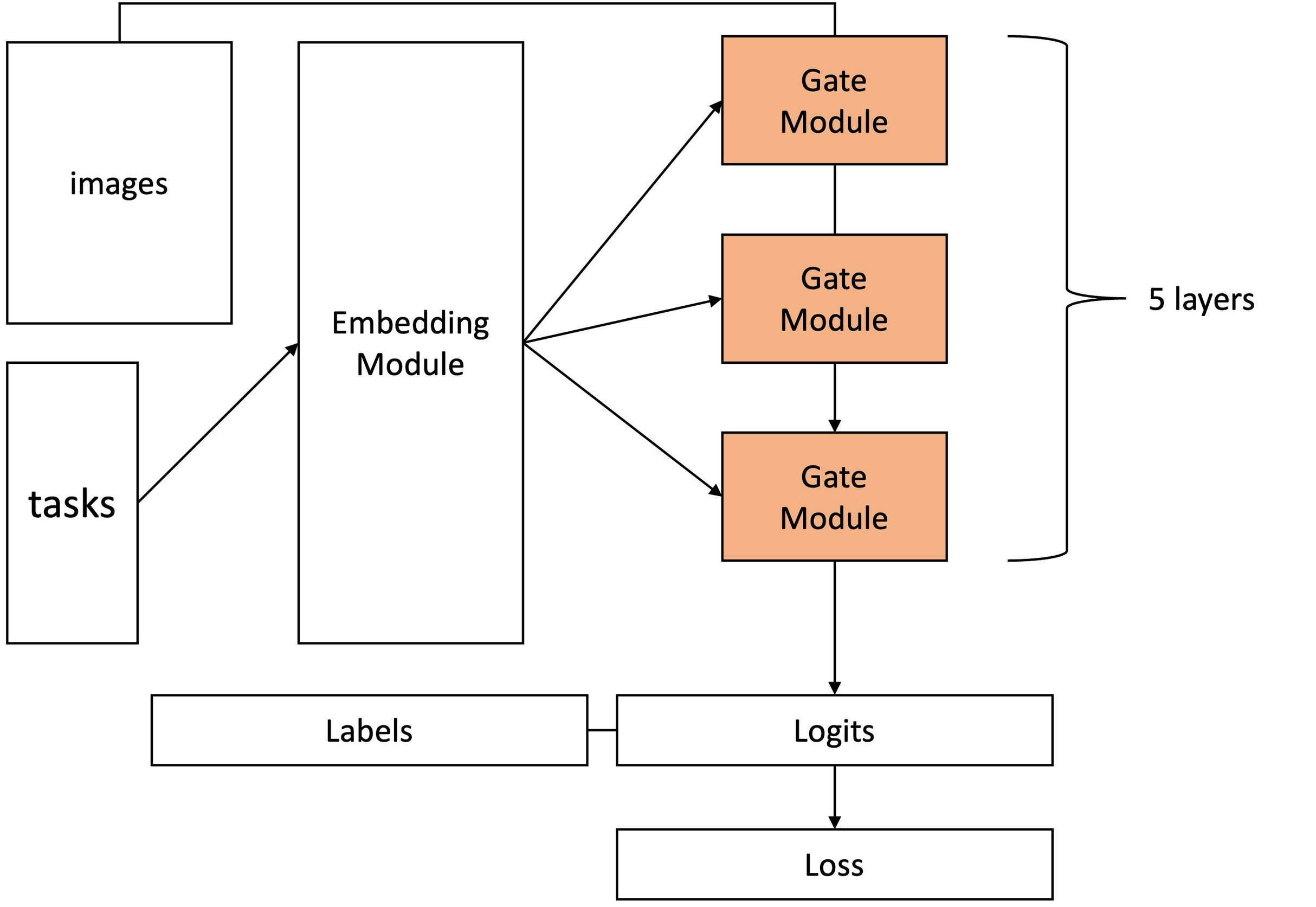
대표적인 방법 중 하나는 HAT(Hard Attetion to the Task)[4]입니다. HAT에서는 이전 데이터에 대한 정보를 담고 있는 가중치들을 Attention기법을 이용하여 학습함으로써 현재 Task에 가장 맞는 정보만을 가져오도록하였습니다.


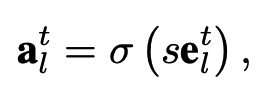
Gate 모듈에서 위에서 정의한 s를 이용하여 gating 과정을 수행합니다. s_max는 고정되어 있는 값이며(무한대로 갈수록 일반 step function에 수렴하고, 0으로 갈수록 1/2에 수렴합니다.) 학습시 배치 내에서 진행정도에 따라 s의 값이 커지게 되는데, 이는 뒤에 들어오는 Task가 덜 잊혀지는 효과를 주게됩니다.
논문에서 제안한 전체적인 아키텍쳐는 아래의 그림과 같습니다.
Reference
[1] DE LANGE, Matthias, et al. A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence, 2021, 44.7: 3366-3385.
[2] REBUFFI, Sylvestre-Alvise, et al. icarl: Incremental classifier and representation learning. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017. p. 2001-2010.
[3] KIRKPATRICK, James, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 2017, 114.13: 3521-3526.
[4] SERRA, Joan, et al. Overcoming catastrophic forgetting with hard attention to the task. In: International Conference on Machine Learning. PMLR, 2018. p. 4548-4557.
'Research > Continual Learning' 카테고리의 다른 글
| Continual Learning - Motivation (0) | 2023.02.18 |
|---|